
Quand le bioréacteur apprend à se piloter lui-même
La fermentation industrielle ressemble de loin à un processus maîtrisé : on inocule, on surveille, on récolte. La réalité est plus turbulente. Dans un fermenteur de grande taille, la distribution des nutriments, la température, l’oxygène dissous et le comportement cellulaire varient constamment. Ce que les ingénieurs appellent l’« effet de scale-up » — la perte de performance entre le pilote et l’industriel — provoque des mois de mise au point et des surcoûts à chaque passage à l’échelle.
L’intelligence artificielle, et plus spécifiquement le machine learning (ML), s’attaque à ce problème en lisant en temps réel les flux de données issus des capteurs, en modélisant les interactions non linéaires entre variables, et en ajustant les paramètres du procédé avant que la déviation ne devienne un problème. Une revue publiée en 2026 dans Biotechnology Advances décrit un cadre où l’IA ne se contente plus d’assister l’opérateur — elle transforme le bioréacteur en « entité cognitive capable de perception, d’apprentissage et d’auto-optimisation ».[1]
Ce n’est pas de la science-fiction. C’est la définition technique du digital twin — un jumeau numérique du bioprocédé qui tourne en parallèle, ingest les données temps réel, et propose ou exécute des corrections en boucle fermée. Les premières implémentations sont opérationnelles dans des contextes de recherche avancée, et des congrès comme Advanced Fermentation Technology 2026 (Adebiotech / Université de Lille, 30 juin – 1er juillet 2026) y consacrent des sessions entières.[2]
Des chiffres concrets, vérifiés, pas des promesses marketing
Le cas le mieux documenté à ce jour concerne la production d’α-amylase par Aspergillus niger. Une équipe de l’East China University of Science and Technology a combiné douze algorithmes de machine learning, de la spectroscopie Raman pour suivre le glucose en temps réel, et une analyse transcriptomique. Résultat : un algorithme Random Forest identifie le glucose comme facteur régulateur dominant — information que les modèles classiques n’auraient pas isolée aussi nettement.
Le contrôle en boucle fermée qui en découle maintient le glucose dans la plage optimale tout au long de la fermentation. Bilan mesuré : +46 % de rendement en α-amylase, –28 heures de fermentation, et un record mondial de production à 15 729 U/mL.[3] Ces chiffres sont publiés dans Bioresource Technology et vérifiables par PMID.
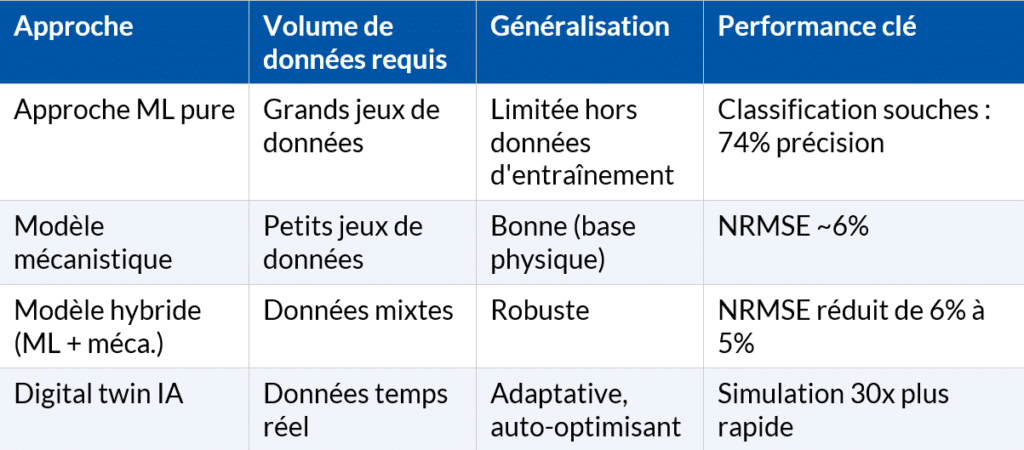
Sur l’optimisation des procédés de fermentation alimentaire, une étude publiée en 2026 dans Food Research International apporte une nuance importante que la communication sur l’IA oublie souvent : les modèles ML surpassent les modèles mécanistiques lorsque les données sont abondantes et diversifiées, mais peinent à généraliser au-delà des conditions d’entraînement. La solution la plus robuste ? Le modèle hybride — coupler un modèle mécanistique (ancré dans la physique du procédé) avec un réseau de neurones correcteur. Ce tandem réduit l’erreur normalisée (NRMSE) de 6 % à 5 %, et compresse le temps de simulation d’un facteur 30.[4]
Traduction pour l’industrie : l’IA n’écrase pas l’expertise scientifique. Elle l’amplifie. Le modèle mécanistique reste la colonne vertébrale ; le ML colmate ses imperfections sur données réelles.
Tableau — Comparatif des approches de modélisation en fermentation
Sources : PMID 41763759 [4] ; PMID 41997461 [1] ; PMID 40930286 [3].
Trois leviers concrets pour la fermentation d’arômes et d’enzymes
- Prédiction et sélection de souches. Les algorithmes de classification permettent de distinguer des souches levuriennes par leurs profils métaboliques, avec une précision de 74 % sur données expérimentales.[4] Pour des applications en arômes naturels — où la sélection de la souche détermine le profil aromatique final — ce type d’outil réduit le nombre de criblages expérimentaux.
- Monitoring en ligne et capteurs avancés. La spectroscopie Raman, les biocapteurs et les soft sensors alimentent les modèles ML en données continues. Une revue de 2025 dans Bioresource Technology (PMID 40170318) synthétise l’état de l’art : le couplage capteurs-IA permet un contrôle dynamique là où les analyses de laboratoire classiques introduisent un délai préjudiciable à la qualité du lot.
- Standardisation des données pour entraîner des modèles robustes. Un préprint arXiv de février 2026 présente PREFER — une ontologie open-source pour la fermentation de précision.[5] Son objectif : rendre les données de bioprocédés « AI-ready » en standardisant leur structure, condition sine qua non pour entraîner des modèles prédictifs transférables d’un procédé à l’autre.
Ce qui freine encore (et ce n’est pas l’algorithme)
Le principal obstacle n’est pas la puissance des algorithmes. C’est la qualité et la quantité des données. Les modèles ML, aussi sophistiqués soient-ils, restent dépendants des données d’entraînement. Un procédé peu documenté, des capteurs mal calibrés, ou une base de données hétérogène produiront des prédictions peu fiables — voire dangereuses si elles pilotent des décisions automatisées.
Second frein : l’interprétabilité. Un algorithme de type boîte noire peut identifier que « le glucose est le facteur critique » sans expliquer pourquoi. Dans des contextes réglementaires (production d’ingrédients pour usage alimentaire ou pharmaceutique), la traçabilité des décisions automatisées est une exigence non négociable.
Troisième frein : le transfert entre échelles. Une revue dans Current Opinion in Biotechnology (PMID 42190350) est explicite : « les souches optimisées en conditions de laboratoire sous-performent souvent dans les bioréacteurs industriels stressés. »[6] L’IA peut anticiper ces dérives — via des modèles multiscales couplant dynamique des fluides et physiologie cellulaire — mais cela suppose des données industrielles, pas seulement des données de pilote.
Le contexte institutionnel : argent et agenda
L’intérêt de l’IA pour la fermentation industrielle n’est plus seulement académique. En mars 2026, le Département de l’Énergie américain a annoncé 293 millions USD pour la Genesis Mission, initiative dédiée à l’accélération de l’IA dans les sciences biologiques, incluant explicitement la biotechnologie et la biofabrication.[7] L’objectif déclaré : compresser les cycles de R&D, développer des jumeaux numériques IA pour le scale-up, et construire des bases de données biologiques « AI-ready » partagées.
En France, le programme Ferments du Futur (INRAE / ANIA, 48,3 M€ financés par France 2030) intègre explicitement l’IA et la science des données pour la conception de consortia microbiens et l’optimisation des procédés.[8] Ce programme constitue aujourd’hui la plateforme nationale la plus importante d’Europe sur le sujet.
Côté marché, les projections sont à prendre avec le recul habituel dû aux estimations de cabinets privés : Precedence Research évalue le marché mondial de la fermentation de précision à 4,91 milliards USD en 2025, avec une projection à 75,76 milliards USD d’ici 2035.[9] Ordre de grandeur pertinent, chiffre exact à qualifier.
Ce que ça change pour Ennolys — et pour ses clients
Ennolys opère exactement à l’intersection de ces développements. Producteur de molécules aromatiques naturelles par fermentation (vanilline, lactones, acétaldéhyde, acides organiques) et CDMO via son offre de services en fermentation & DSP, Ennolys travaille sur les mêmes variables que celles que l’IA apprend à optimiser : souche, substrat, température, cinétique, rendement, profil aromatique.
L’intégration de modèles ML dans la mise au point des procédés n’est pas un projet futur — c’est un nouvel avantage concurrentiel. Les clients industriels qui font appel à un CDMO pour le scale-up de leur bioprocédé ont aujourd’hui accès à des outils de prédiction de plus en plus accessibles. La valeur d’un partenaire CDMO ne se joue plus seulement sur l’équipement ou l’expérience : elle se joue sur la capacité à intégrer les données, à modéliser les transitions d’échelle, et à garantir la reproductibilité du procédé.
La question n’est pas de savoir si l’IA va transformer la fermentation industrielle. Elle est déjà en train de le faire, dans les laboratoires et dans certaines unités de production avancées. Les algorithmes existent, les cas d’usage sont documentés, les financements publics sont en place. Ce qui déterminera l’écart de compétitivité dans les trois prochaines années, c’est la capacité à instrumenter les procédés existants et à mettre les données en qualité — avant de les confier à un modèle.
Vous travaillez sur un projet de fermentation industrielle ?
Vous intégrez l’IA dans vos bioprocédés ou explorez la fermentation de précision ?
Ennolys et son pôle CDMO accompagnent vos projets de fermentation industrielle, de la mise au point jusqu’à la production industrielle en passant par le scale-up. Contactez nos équipes pour discuter de votre projet.

FAQ — Fermentation et intelligence artificielle
1. L’IA peut-elle remplacer l’expertise du microbiologiste ?
Non — et les données le confirment. Les modèles ML purs échouent lorsque les données sont rares ou hors de leur domaine d’entraînement. L’expertise scientifique reste indispensable pour définir les variables pertinentes, interpréter les anomalies et valider les décisions automatisées. L’IA augmente le microbiologiste ; elle ne le remplace pas.
2. Qu’est-ce qu’un digital twin appliqué à la fermentation ?
Un jumeau numérique est un modèle computationnel qui réplique en temps réel le comportement du bioprocédé réel. Il ingère les données des capteurs, prédit les dérives, propose des corrections et peut piloter automatiquement certains paramètres (température, débit d’alimentation, pH). En fermentation, il résout le problème du scale-up en simulant les comportements à grande échelle avant de les expérimenter physiquement.
3. Quels types de fermentation bénéficient le plus de l’IA aujourd’hui ?
Les procédés les mieux documentés — fermentations enzymatiques, production de métabolites secondaires, brassage, vinification — offrent les bases de données les plus denses et donc les gains IA les plus démontrés. En arômes naturels, la sélection de souches et l’optimisation des conditions de culture sont les deux points d’entrée les plus immédiats.
4. L’IA en fermentation, c’est accessible à toutes les tailles d’entreprises ?
Les outils de base (Random Forest, réseaux de neurones légers, soft sensors) sont open-source et intégrables dans des workflows existants. Ce qui reste coûteux, c’est l’instrumentation des fermenteurs (capteurs en ligne, spectroscopie Raman) et la mise en qualité des données. Le recours à un partenaire CDMO équipé est souvent le chemin le plus rapide pour accéder à ces capacités sans investissement propre.
5. Quelle différence entre fermentation de précision et fermentation optimisée par IA ?
La fermentation de précision désigne l’utilisation de micro-organismes génétiquement modifiés pour produire des molécules spécifiques (protéines, enzymes, arômes). L’IA est l’un des outils qui l’accélère — mais elle s’applique aussi bien à des procédés de fermentation traditionnels non modifiés. L’IA est transversale ; la fermentation de précision est un type de procédé.
Sources
[1] Gu Q, Yu J, Liu Y, et al.. Harnessing bioreactor heterogeneity: From gradient understanding to autonomous control via multiscale modeling and intelligent optimization. Biotechnology Advances. 2026. PMID : 41997461. DOI : 10.1016/j.biotechadv.2026.108899
[2] Adebiotech / Université de Lille.. Advanced Fermentation Technology 2026 (AFT) — Programme officiel. asso.adebiotech.org. 2026.
[3] Wang Y, Wang Y, Xu F, et al.. Artificial intelligence-driven fermentation optimization for α-amylase hyperproduction enabled by Raman monitoring and metabolic network analysis. Bioresource Technology. 2025. PMID : 40930286. DOI : 10.1016/j.biortech.2025.133287
[4] Campo-Manzanares N, Moimenta AR, Balsa-Canto E.. Critical assessment of machine learning approaches for classification, dynamic prediction and surrogate modeling in food fermentation. Food Research International. 2026. PMID : 41763759. DOI : 10.1016/j.foodres.2026.118403
[5] Auteurs collectifs (préprint).. PREFER: An Ontology for the PREcision FERmentation Community. arXiv. 2026. DOI : arXiv:2602.16755
[6] Yuan S, Xu V, Muddana C, et al.. From design-build-test-learn cycles to AI-driven digital twins for bioprocess scale-up in the Genesis Mission era. Current Opinion in Biotechnology. 2026. PMID : 42190350. DOI : 10.1016/j.copbio.2026.103516
[7] U.S. Department of Energy.. DOE announces USD 293 million for the Genesis Mission to support AI research and development in biosciences. globaltradealert.org / thelconsulting.com. 2026.
[8] INRAE / ANIA.. Programme Ferments du Futur — France 2030. hal.inrae.fr. 2023. DOI : hal-04176537
[9] Precedence Research.. Precision Fermentation Market Size, Share, Trends & Forecast 2025–2035. precedenceresearch.com. 2026.
