
When the Bioreactor learns to run itself
Industrial fermentation looks manageable from a distance: inoculate, monitor, harvest. The reality is far messier. In large-scale fermenters, nutrient distribution, temperature, dissolved oxygen, and cellular behavior fluctuate constantly. What engineers call the “scale-up effect” — the performance gap between pilot and industrial scale — costs months of process development and significant overruns at every transition.
Artificial intelligence, and machine learning (ML) in particular, tackles this problem by reading real-time sensor data streams, modeling nonlinear interactions between variables, and adjusting process parameters before a deviation becomes a failure. A 2026 review in Biotechnology Advances describes a framework where AI no longer simply assists the operator — it turns the bioreactor into “a cognitive entity capable of perception, learning, and self-optimization.”[1]
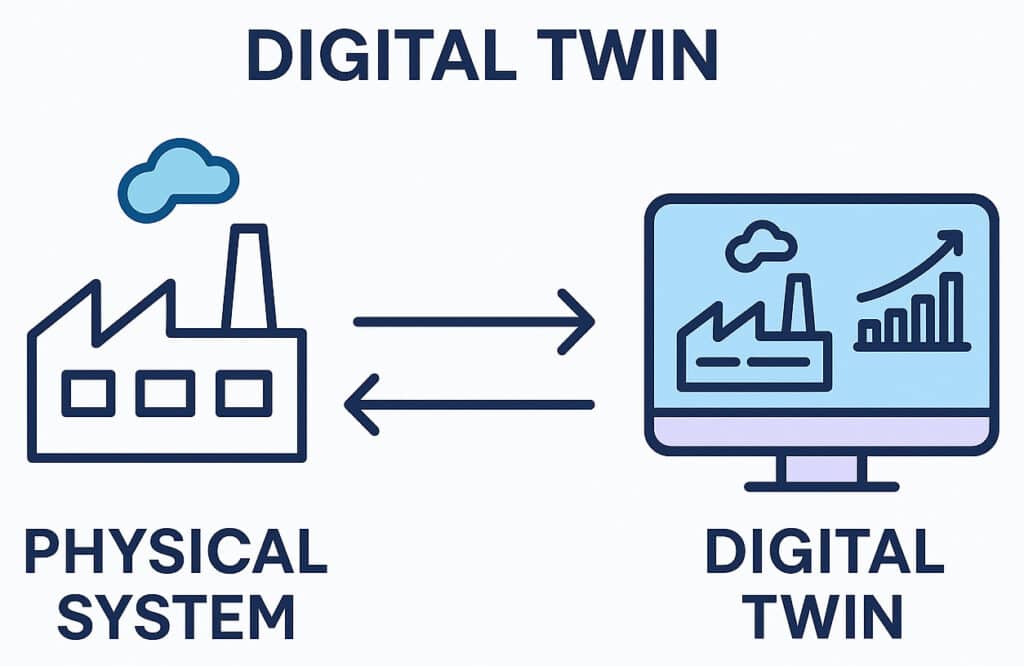
That’s not science fiction. It’s the technical definition of a digital twin — a computational replica of the bioprocess running in parallel, ingesting real-time data, and proposing or executing closed-loop corrections. Early implementations are already operational in advanced research settings, and events like Advanced Fermentation Technology 2026 (Adebiotech / Université de Lille, June 30 – July 1, 2026) are dedicating entire sessions to the topic.[2]
Hard numbers, not marketing claims
The best-documented case to date involves α-amylase production by Aspergillus niger. A team at East China University of Science and Technology combined twelve ML algorithms, Raman spectroscopy for real-time glucose monitoring, and transcriptomic analysis. A Random Forest algorithm identified glucose as the dominant regulatory factor — something conventional models hadn’t isolated with that clarity.
The resulting closed-loop control system maintained glucose within the optimal range throughout fermentation. The measured outcome: +46% α-amylase yield, −28 hours of fermentation time, and a world production record of 15,729 U/mL.[3] These figures are published in Bioresource Technology and traceable by PMID.
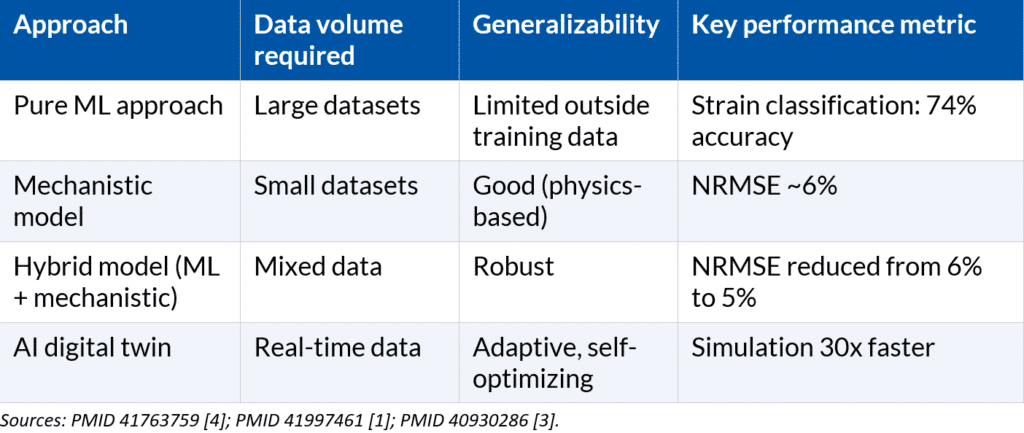
A 2026 study in Food Research International adds a nuance that AI coverage often glosses over: pure ML models outperform mechanistic models when data is abundant and varied, but they struggle to generalize beyond their training conditions. The most robust solution? The hybrid model — pairing a mechanistic model (grounded in process physics) with a neural network corrector. This combination reduces normalized error (NRMSE) from 6% to 5% and compresses simulation time by a factor of 30.[4]
The practical takeaway: AI doesn’t replace scientific expertise. It amplifies it. The mechanistic model remains the backbone; ML patches its blind spots on real-world data.
Table — Modeling Approaches in Fermentation: A Comparative Overview
3 practical levers for flavor and enzyme fermentation
- Strain prediction and selection. Classification algorithms can distinguish yeast strains by their metabolic profiles, achieving 74% accuracy on experimental data.[4] In natural flavor applications — where strain selection determines the final aromatic profile — these tools reduce the number of screening experiments needed.
- Online monitoring and advanced sensors. Raman spectroscopy, biosensors, and soft sensors continuously feed ML models. A 2025 review in Bioresource Technology (PMID 40170318) synthesizes the state of the art: sensor-AI coupling enables dynamic control where traditional lab analysis introduces time lags that compromise batch quality.
- Data standardization for robust model training. A February 2026 arXiv preprint introduces PREFER — an open-source ontology for precision fermentation.[5] Its goal: making bioprocess data “AI-ready” by standardizing its structure — a prerequisite for training predictive models that transfer across processes.
What’s still holding things back (and it’s not the algorithm)
The main obstacle isn’t algorithmic power. It’s data quality and volume. No matter how sophisticated, ML models are only as good as their training data. A poorly documented process, miscalibrated sensors, or a heterogeneous dataset will produce unreliable — potentially dangerous — predictions if those predictions drive automated decisions.
The second barrier is interpretability. A black-box algorithm can flag glucose as “the critical variable” without explaining why. In regulated contexts — food ingredient or pharmaceutical production — the traceability of automated decisions is a non-negotiable requirement.
The third barrier is cross-scale transfer. A review in Current Opinion in Biotechnology (PMID 42190350) is direct: “strains optimized under laboratory conditions frequently underperform in stressed industrial bioreactors.”[6] AI can anticipate these deviations — through multiscale models coupling fluid dynamics and cellular physiology — but that requires industrial data, not just pilot-scale data.
The institutional picture: money and momentum
Interest in AI for industrial fermentation has moved well beyond academia. In March 2026, the U.S. Department of Energy announced $293 million for the Genesis Mission, an initiative to accelerate AI in the biological sciences, explicitly including biotechnology and biomanufacturing.[7] The stated goals: compress R&D cycles, develop AI-powered digital twins for scale-up, and build shared “AI-ready” biological databases.
In France, the Ferments du Futur program (INRAE / ANIA, €48.3M funded through France 2030) explicitly integrates AI and data science for microbial consortia design and process optimization.[8] It is currently the largest national platform of its kind in Europe.
On the market side, analyst projections should be read as order-of-magnitude estimates rather than firm figures: Precedence Research values the global precision fermentation market at $4.91 billion in 2025, with a projection of $75.76 billion by 2035.[9] The direction of travel is clear; the exact trajectory less so.
What this means for Ennolys — and its clients
Ennolys operates precisely at the intersection of these developments. As a producer of natural aroma molecules through fermentation (vanillin, lactones, acetaldehyde, organic acids) and a CDMO through its fermentation and DSP services, Ennolys works on the same variables AI is learning to optimize: strain, substrate, temperature, kinetics, yield, and aromatic profile.
Integrating ML models into process development is no longer a future project — it’s an emerging competitive differentiator. Industrial clients turning to a CDMO for bioprocess scale-up now have access to increasingly accessible predictive tools. The value of a CDMO partner is no longer determined solely by equipment or experience: it comes down to the ability to integrate data, model scale-up transitions, and guarantee process reproducibility.
The question isn’t whether AI will transform industrial fermentation. It already is, in advanced research labs and in some production facilities. The algorithms exist. The monitoring tools are accessible. The public funding is in place. What will determine the competitive gap over the next three years is the capacity to instrument existing processes and get data into shape — before handing it to a model.
Are you working on an industrial fermentation project?
Are you integrating AI into your bioprocesses or exploring precision fermentation?
Ennolys and its CDMO division support your industrial fermentation projects—from development to industrial-scale production, including scale-up. Contact our teams to discuss your project.

FAQ — AI and Industrial Fermentation
1. Can AI replace the microbiologist?
No — and the data backs that up. Pure ML models fail when data is scarce or out of distribution. Scientific expertise remains essential to define the right variables, interpret anomalies, and validate automated decisions. AI enhances the microbiologist’s capabilities; it does not replace them.
2. What is a digital twin in a fermentation context?
A digital twin is a computational model that replicates the behavior of a real bioprocess in real time. It ingests sensor data, predicts deviations, proposes corrections, and can automatically control certain parameters (temperature, feed rate, pH). In fermentation, it addresses the scale-up problem by simulating large-scale behavior before physically running the experiment.
3. Which fermentation types benefit most from AI today?
The best-documented processes — enzyme fermentation, secondary metabolite production, brewing, winemaking — offer the densest datasets and therefore the most demonstrable AI gains. In natural flavors, strain selection and culture condition optimization are the two most immediate entry points.
4. Is AI in fermentation accessible to smaller companies?
The core tools (Random Forest, lightweight neural networks, soft sensors) are open-source and can be integrated into existing workflows. What remains costly is fermenter instrumentation (inline sensors, Raman spectroscopy) and data quality management. Partnering with an equipped CDMO is often the fastest path to these capabilities without internal capital investment.
5. What’s the difference between precision fermentation and AI-optimized fermentation?
Precision fermentation refers to the use of genetically engineered microorganisms to produce specific molecules (proteins, enzymes, flavors). AI is one of the tools accelerating it — but it applies equally to conventional, unmodified fermentation processes. AI is a cross-cutting technology; precision fermentation is a process category.
Sources
[1] Gu Q, Yu J, Liu Y, et al.. Harnessing bioreactor heterogeneity: From gradient understanding to autonomous control via multiscale modeling and intelligent optimization. Biotechnology Advances. 2026. PMID: 41997461. DOI: 10.1016/j.biotechadv.2026.108899
[2] Adebiotech / Université de Lille.. Advanced Fermentation Technology 2026 (AFT) — Official Program. asso.adebiotech.org. 2026.
[3] Wang Y, Wang Y, Xu F, et al.. Artificial intelligence-driven fermentation optimization for α-amylase hyperproduction enabled by Raman monitoring and metabolic network analysis. Bioresource Technology. 2025. PMID: 40930286. DOI: 10.1016/j.biortech.2025.133287
[4] Campo-Manzanares N, Moimenta AR, Balsa-Canto E.. Critical assessment of machine learning approaches for classification, dynamic prediction and surrogate modeling in food fermentation. Food Research International. 2026. PMID: 41763759. DOI: 10.1016/j.foodres.2026.118403
[5] Collective authors (preprint).. PREFER: An Ontology for the PREcision FERmentation Community. arXiv. 2026. DOI: arXiv:2602.16755
[6] Yuan S, Xu V, Muddana C, et al.. From design-build-test-learn cycles to AI-driven digital twins for bioprocess scale-up in the Genesis Mission era. Current Opinion in Biotechnology. 2026. PMID: 42190350. DOI: 10.1016/j.copbio.2026.103516
[7] U.S. Department of Energy.. DOE announces $293 million for the Genesis Mission to support AI research and development in biosciences. globaltradealert.org / thelconsulting.com. 2026.
[8] INRAE / ANIA.. Programme Ferments du Futur — France 2030. hal.inrae.fr. 2023. DOI: hal-04176537
[9] Precedence Research.. Precision Fermentation Market Size, Share, Trends & Forecast 2025–2035. precedenceresearch.com. 2026.
